Video understanding is a challenging problem that requires reasoning about both spatial information (e.g., for objects in a scene, including their locations and relations) and temporal information for activities or events shown in a video. There are many video understanding applications and tasks, such as understanding the semantic content of web videos and robot perception. However, current works, such as ViViT and TimeSFormer, densely process the video and require significant compute, especially as model size plus video length and resolution increase.
In “Rethinking Video ViTs: Sparse Video Tubes for Joint Image and Video Learning”, to be presented at CVPR 2023, we introduce a simple technique that turns a Vision Transformer (ViT) model image encoder into an efficient video backbone using sparse video tubes (learnable visual representations of samples from the video) to reduce the model’s compute needs. This approach can seamlessly process both images and videos, which allows it to leverage both image and video data sources during training. This training further enables our sparse tubes ViT model to coalesce image and video backbones together to serve a dual role as either an image or video backbone (or both), depending on the input. We demonstrate that this model is scalable, can be adapted to large pre-trained ViTs without requiring full fine-tuning, and achieves state-of-the-art results across many video classification benchmarks.
 |
| Using sparse video tubes to sample a video, combined with a standard ViT encoder, leads to an efficient visual representation that can be seamlessly shared with image inputs. |
Our sparse tube ViT uses a standard ViT backbone, consisting of a stack of Transformer layers, that processes video information. Previous methods, such as ViViT, densely tokenize the video and then apply factorized attention, i.e., the attention weights for each token are computed separately for the temporal and spatial dimensions. In the standard ViT architecture, self-attention is computed over the whole token sequence. When using videos as input, token sequences become quite long, which can make this computation slow. Instead, in the method we propose, the video is sparsely sampled using video tubes, which are 3D learnable visual representations of various shapes and sizes (described in more detail below) from the video. These tubes are used to sparsely sample the video using a large temporal stride, i.e., when a tube kernel is only applied to a few locations in the video, rather than every pixel.
By sparsely sampling the video tubes, we can use the same global self-attention module, rather than factorized attention like ViViT. We experimentally show that the addition of factorized attention layers can harm the performance due to the uninitialized weights. This single stack of transformer layers in the ViT backbone also enables better sharing of the weights and improves performance. Sparse video tube sampling is done by using a large spatial and temporal stride that selects tokens on a fixed grid. The large stride reduces the number of tokens in the full network, while still capturing both spatial and temporal information and enabling the efficient processing of all tokens.
Video tubes are 3D grid-based cuboids that can have different shapes or categories and capture different information with strides and starting locations that can overlap. In the model, we use three distinct tube shapes that capture: (1) only spatial information (resulting in a set of 2D image patches), (2) long temporal information (over a small spatial area), and (3) both spatial and temporal information equally. Tubes that capture only spatial information can be applied to both image and video inputs. Tubes that capture long temporal information or both temporal and spatial information equally are only applied to video inputs. Depending on the input video size, the three tube shapes are applied to the model multiple times to generate tokens.
A fixed position embedding, which captures the global location of each tube (including any strides, offsets, etc.) relative to all the other tubes, is applied to the video tubes. Different from the previous learned position embeddings, this fixed one better enables sparse, overlapping sampling. Capturing the global location of the tube helps the model know where each came from, which is especially helpful when tubes overlap or are sampled from distant video locations. Next, the tube features are concatenated together to form a set of N tokens. These tokens are processed by a standard ViT encoder. Finally, we apply an attention pooling to compress all the tokens into a single representation and input to a fully connected (FC) layer to make the classification (e.g., playing soccer, swimming, etc.).
 |
| Our video ViT model works by sampling sparse video tubes from the video (shown at the bottom) to enable either or both image or video inputs to be seamlessly processed. These tubes have different shapes and capture different video features. Tube 1 (yellow) only captures spatial information, resulting in a set of 2D patches that can be applied to image inputs. Tube 2 (red) captures temporal information and some spatial information and tube 3 (green) equally captures both temporal and spatial information (i.e., the spatial size of the tube x and y are the same as the number of frames t). Tubes 2 and 3 can only be applied to video inputs. The position embedding is added to all the tube features. |
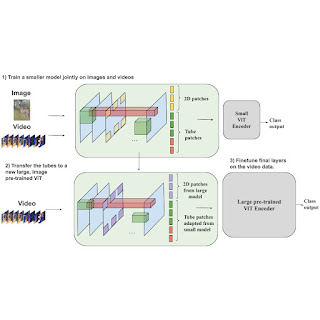
The process of building video backbones is computationally intensive, but our sparse tube ViT model enables computationally efficient scaling of video models, leveraging previously trained image backbones. Since image backbones can be adapted to a video backbone, large image backbones can be turned into large video backbones. More specifically, one can transfer the learned video feature representations from a small tube ViT to a large pre-trained image ViT and train the resulting model with video data for only a few steps, as opposed to a full training from scratch.
 |
| Our approach enables scaling a sparse tube ViT in a more efficient way. Specifically, the video features from a small video ViT (top network) can be transferred to a large, pre-trained image ViT (bottom network), and further fine-tuned. This requires fewer training steps to achieve strong performance with the large model. This is beneficial as large video models might be prohibitively expensive to train from scratch. |
We evaluate our sparse tube ViT approach using Kinetics-400 (shown below), Kinetics-600 and Kinetics-700 datasets and compare its performance to a long list of prior methods. We find that our approach outperforms all prior methods. Importantly, it outperforms all state-of-the-art methods trained jointly on image+video datasets.
 |
| Performance compared to several prior works on the popular Kinetics-400 video dataset. Our sparse tube ViT outperforms state-of-the-art methods. |
Furthermore, we test our sparse tube ViT model on the Something-Something V2 dataset, which is commonly used to evaluate more dynamic activities, and also report that it outperforms all prior state-of-the-art approaches.
 |
| Performance on the Something-Something V2 video dataset. |
It is interesting to understand what kind of rudimentary features are being learned by the proposed model. We visualize them below, showing both the 2D patches, which are shared for both images and videos, and video tubes. These visualizations show the 2D or 3D information being captured by the projection layer. For example, in the 2D patches, various common features, like edges and colors, are detected, while the 3D tubes capture basic shapes and how they may change over time.
 |
| Visualizations of patches and tubes learned the sparse tube ViT model. Top row are the 2D patches and the remaining two rows are snapshots from the learned video tubes. The tubes show each patch for the 8 or 4 frames to which they are applied. |
We have presented a new sparse tube ViT, which can turn a ViT encoder into an efficient video model, and can seamlessly work with both image and video inputs. We also showed that large video encoders can be bootstrapped from small video encoders and image-only ViTs. Our approach outperforms prior methods across several popular video understanding benchmarks. We believe that this simple representation can facilitate much more efficient learning with input videos, seamlessly incorporate either image or video inputs and effectively eliminate the bifurcation of image and video models for future multimodal understanding.
This work is conducted by AJ Piergiovanni, Weicheng Kuo and Anelia Angelova, who are now at Google DeepMind. We thank Abhijit Ogale, Luowei Zhou, Claire Cui and our colleagues in Google Research for their helpful discussions, comments, and support.
Why Snowflake Postgres is different Most data replication tools work by wedging a separate service between your database and your […]
Get started with Snowflake Apps Hundreds of providers distribute apps and data products through Snowflake Marketplace. Thousands of companies already […]
The pace of AI evolution is entirely unprecedented. But for organizations to truly capitalize on this momentum, it isn’t just […]
Our services help both the big and small organisations in the identification of security breaches and provide outclass solutions to prevent any potential harm.