The recent progress in generative AI unlocked the possibility of creating new content in several different domains, including text, vision and audio. These models often rely on the fact that raw data is first converted to a compressed format as a sequence of tokens. In the case of audio, neural audio codecs (e.g., SoundStream or EnCodec) can efficiently compress waveforms to a compact representation, which can be inverted to reconstruct an approximation of the original audio signal. Such a representation consists of a sequence of discrete audio tokens, capturing the local properties of sounds (e.g., phonemes) and their temporal structure (e.g., prosody). By representing audio as a sequence of discrete tokens, audio generation can be performed with Transformer-based sequence-to-sequence models — this has unlocked rapid progress in speech continuation (e.g., with AudioLM), text-to-speech (e.g., with SPEAR-TTS), and general audio and music generation (e.g., AudioGen and MusicLM). Many generative audio models, including AudioLM, rely on auto-regressive decoding, which produces tokens one by one. While this method achieves high acoustic quality, inference (i.e., calculating an output) can be slow, especially when decoding long sequences.
To address this issue, in “SoundStorm: Efficient Parallel Audio Generation”, we propose a new method for efficient and high-quality audio generation. SoundStorm addresses the problem of generating long audio token sequences by relying on two novel elements: 1) an architecture adapted to the specific nature of audio tokens as produced by the SoundStream neural codec, and 2) a decoding scheme inspired by MaskGIT, a recently proposed method for image generation, which is tailored to operate on audio tokens. Compared to the autoregressive decoding approach of AudioLM, SoundStorm is able to generate tokens in parallel, thus decreasing the inference time by 100x for long sequences, and produces audio of the same quality and with higher consistency in voice and acoustic conditions. Moreover, we show that SoundStorm, coupled with the text-to-semantic modeling stage of SPEAR-TTS, can synthesize high-quality, natural dialogues, allowing one to control the spoken content (via transcripts), speaker voices (via short voice prompts) and speaker turns (via transcript annotations), as demonstrated by the examples below:
| Input: Text (transcript used to drive the audio generation in bold) | Something really funny happened to me this morning. | Oh wow, what? | Well, uh I woke up as usual. | Uhhuh | Went downstairs to have uh breakfast. | Yeah | Started eating. Then uh 10 minutes later I realized it was the middle of the night. | Oh no way, that’s so funny! | I didn’t sleep well last night. | Oh, no. What happened? | I don’t know. I I just couldn’t seem to uh to fall asleep somehow, I kept tossing and turning all night. | That’s too bad. Maybe you should uh try going to bed earlier tonight or uh maybe you could try reading a book. | Yeah, thanks for the suggestions, I hope you’re right. | No problem. I I hope you get a good night’s sleep | ||
| Input: Audio prompt |
|
| ||
| Output: Audio prompt + generated audio |
|
|
In our previous work on AudioLM, we showed that audio generation can be decomposed into two steps: 1) semantic modeling, which generates semantic tokens from either previous semantic tokens or a conditioning signal (e.g., a transcript as in SPEAR-TTS, or a text prompt as in MusicLM), and 2) acoustic modeling, which generates acoustic tokens from semantic tokens. With SoundStorm we specifically address this second, acoustic modeling step, replacing slower autoregressive decoding with faster parallel decoding.
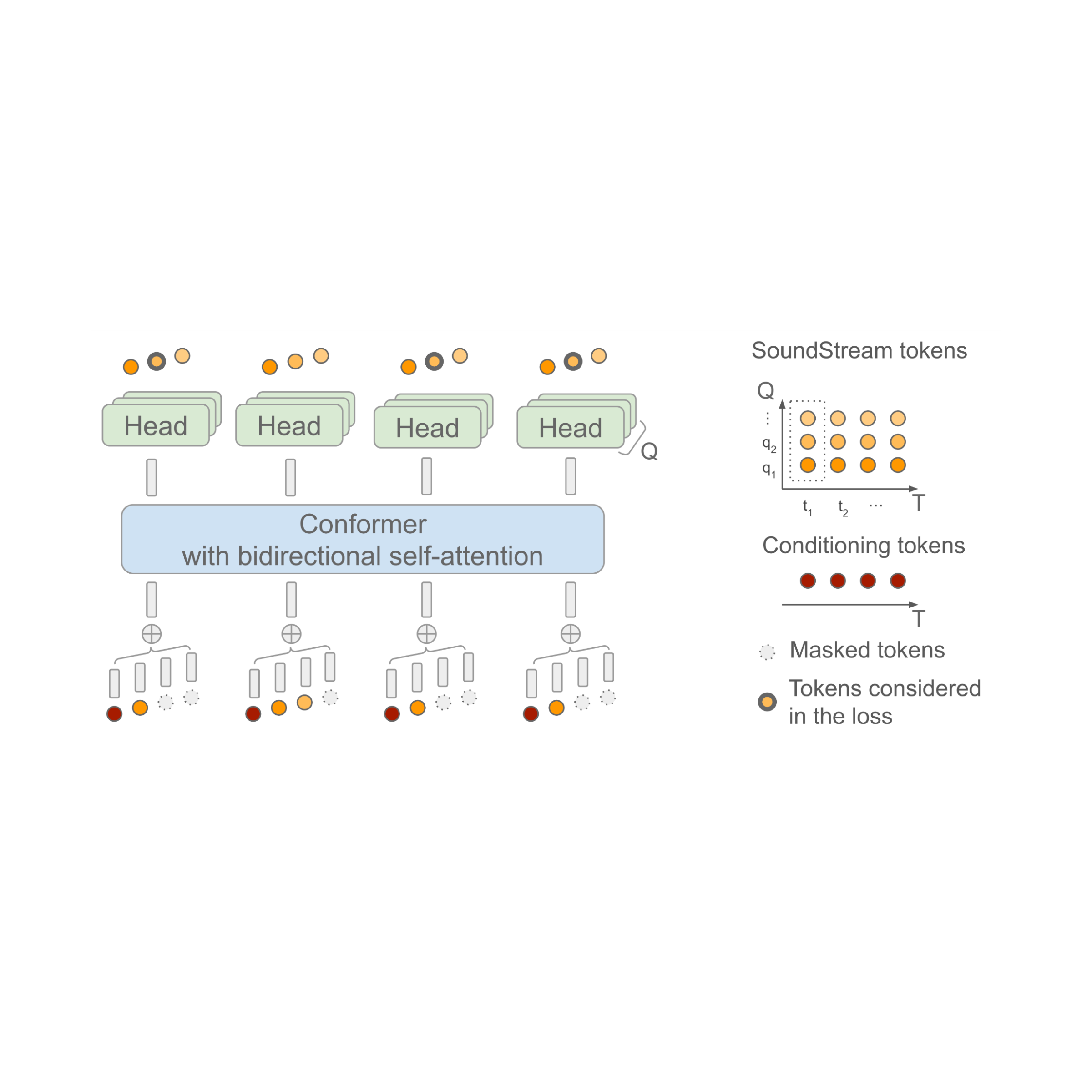
SoundStorm relies on a bidirectional attention-based Conformer, a model architecture that combines a Transformer with convolutions to capture both local and global structure of a sequence of tokens. Specifically, the model is trained to predict audio tokens produced by SoundStream given a sequence of semantic tokens generated by AudioLM as input. When doing this, it is important to take into account the fact that, at each time step t, SoundStream uses up to Q tokens to represent the audio using a method known as residual vector quantization (RVQ), as illustrated below on the right. The key intuition is that the quality of the reconstructed audio progressively increases as the number of generated tokens at each step goes from 1 to Q.
At inference time, given the semantic tokens as input conditioning signal, SoundStorm starts with all audio tokens masked out, and fills in the masked tokens over multiple iterations, starting from the coarse tokens at RVQ level q = 1 and proceeding level-by-level with finer tokens until reaching level q = Q.
There are two crucial aspects of SoundStorm that enable fast generation: 1) tokens are predicted in parallel during a single iteration within a RVQ level and, 2) the model architecture is designed in such a way that the complexity is only mildly affected by the number of levels Q. To support this inference scheme, during training a carefully designed masking scheme is used to mimic the iterative process used at inference.
 |
| SoundStorm model architecture. T denotes the number of time steps and Q the number of RVQ levels used by SoundStream. The semantic tokens used as conditioning are time-aligned with the SoundStream frames. |
We demonstrate that SoundStorm matches the quality of AudioLM’s acoustic generator, replacing both AudioLM’s stage two (coarse acoustic model) and stage three (fine acoustic model). Furthermore, SoundStorm produces audio 100x faster than AudioLM’s hierarchical autoregressive acoustic generator (top half below) with matching quality and improved consistency in terms of speaker identity and acoustic conditions (bottom half below).
 |
| Runtimes of SoundStream decoding, SoundStorm and different stages of AudioLM on a TPU-v4. |
 |
| Acoustic consistency between the prompt and the generated audio. The shaded area represents the inter-quartile range. |
We acknowledge that the audio samples produced by the model may be influenced by the unfair biases present in the training data, for instance in terms of represented accents and voice characteristics. In our generated samples, we demonstrate that we can reliably and responsibly control speaker characteristics via prompting, with the goal of avoiding unfair biases. A thorough analysis of any training data and its limitations is an area of future work in line with our responsible AI Principles.
In turn, the ability to mimic a voice can have numerous malicious applications, including bypassing biometric identification and using the model for the purpose of impersonation. Thus, it is crucial to put in place safeguards against potential misuse: to this end, we have verified that the audio generated by SoundStorm remains detectable by a dedicated classifier using the same classifier as described in our original AudioLM paper. Hence, as a component of a larger system, we believe that SoundStorm would be unlikely to introduce additional risks to those discussed in our earlier papers on AudioLM and SPEAR-TTS. At the same time, relaxing the memory and computational requirements of AudioLM would make research in the domain of audio generation more accessible to a wider community. In the future, we plan to explore other approaches for detecting synthesized speech, e.g., with the help of audio watermarking, so that any potential product usage of this technology strictly follows our responsible AI Principles.
We have introduced SoundStorm, a model that can efficiently synthesize high-quality audio from discrete conditioning tokens. When compared to the acoustic generator of AudioLM, SoundStorm is two orders of magnitude faster and achieves higher temporal consistency when generating long audio samples. By combining a text-to-semantic token model similar to SPEAR-TTS with SoundStorm, we can scale text-to-speech synthesis to longer contexts and generate natural dialogues with multiple speaker turns, controlling both the voices of the speakers and the generated content. SoundStorm is not limited to generating speech. For example, MusicLM uses SoundStorm to synthesize longer outputs efficiently (as seen at I/O).
The work described here was authored by Zalán Borsos, Matt Sharifi, Damien Vincent, Eugene Kharitonov, Neil Zeghidour and Marco Tagliasacchi. We are grateful for all discussions and feedback on this work that we received from our colleagues at Google.
Why Snowflake Postgres is different Most data replication tools work by wedging a separate service between your database and your […]
Get started with Snowflake Apps Hundreds of providers distribute apps and data products through Snowflake Marketplace. Thousands of companies already […]
The pace of AI evolution is entirely unprecedented. But for organizations to truly capitalize on this momentum, it isn’t just […]
Our services help both the big and small organisations in the identification of security breaches and provide outclass solutions to prevent any potential harm.