Today Snowflake is launching and open-sourcing with an Apache 2.0 license the Snowflake Arctic embed family of models. Based on the Massive Text Embedding Benchmark (MTEB) Retrieval Leaderboard, the largest Arctic embed model with only 334 million parameters is the only one to surpass average retrieval performance of 55.9, a feat only less practical to deploy models with over 1 billion parameters are able to achieve. The family of five models are available on Hugging Face for immediate use and in Snowflake Cortex embed function (in private preview), available soon. The models, which deliver leading retrieval performance, give organizations a new edge when combining proprietary datasets with LLMs as part of a Retrieval Augmented Generation (RAG) or semantic search service. These impressive embedding models directly implement the technical expertise, proprietary search knowledge, and research and development that Snowflake acquired last May via Neeva.
Highlights from this family of embedding models include:
Embedding models are a crucial component of most modern AI workloads. From powering search to empowering RAG agents with proprietary information, the ability to find the most relevant content is a foundation of AI systems. As part of Snowflake’s commitment to AI excellence, we sought to deeply understand text embedding models to deliver the best experience for customer products leveraging Snowflake for their search needs. Leveraging our rich expertise in search and the state-of-the-art research in this space, we set out to create the best open-source text embedding models from the ground up.
Starting with our understanding of what is needed to make search great and combining it with state-of-the-art research led us to rebuild text embedding from the ground up. As we alluded to in our recent discussion on how to train a state-of-the-art embedding model and how to use Snowflake to process training data, we analyzed text embedding models from first principles and then went ahead and trained these models end to end in Snowflake. This tooling and our deep understanding of search allowed us to create this suite of models, which outperform previous state-of-the-art models across all our embedding variants. Simply stated, our models are unmatched for their quality and TCO for enterprises of any size seeking to power their embedding workflows.
Evaluating the quality of retrieval systems in a nonproprietary way can be difficult; building on decades of academic research, the Massive Text Embedding Benchmark (MTEB) has emerged as a standard benchmark. It is a collection of tasks that measures the performance of retrieval systems across seven tasks: classification, clustering, pair classification, re-ranking, retrieval, STS (semantic textual similarity), and summarization. It includes 56 datasets from various domains and with various text lengths. The Snowflake Arctic embed models firmly focus on empowering real-world retrieval workloads, and as a result, we focus on the retrieval portion of MTEB.
As of April 2024, each of our models is ranked first among embedding models of similar size, and our largest model is only outperformed by open-source models with over 20 times (and four times for closed models) the number of parameters or closed-source models that do not disclose any form of model characteristics. We understand that testing against a single benchmark can both understate and overstate the impact of variation of embedding models on customer workloads, which is what Snowflake ultimately cares about. This is why we are working on new benchmarks focusing on real-world use cases with real-world datasets in the next benchmarking phase. We will update the broader community when we have a large enough sample.
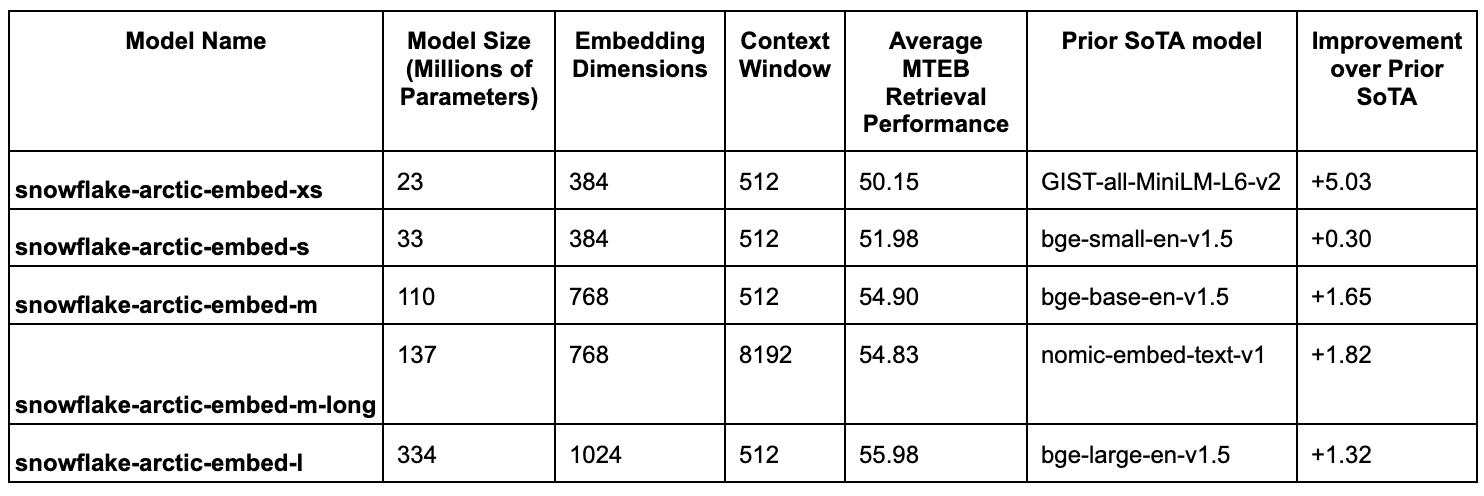
Snowflake’s arctic-embed models are a family of 5 text embedding models that range in context window and size (number of parameters). The model sizes range from 23 to 334 million parameters, and one of the models has an extended context window to give enterprises a full range of options that best match their latency, cost, and retrieval performance requirements. In the table below, we cover model sizes and their relative performance improvement compared to the prior best-performing model with a similar size. The metric for quality is NDCG@10 on the MTEB Retrieval leaderboard, and we compare each model’s performance with associated open-source models with similar parameter count.
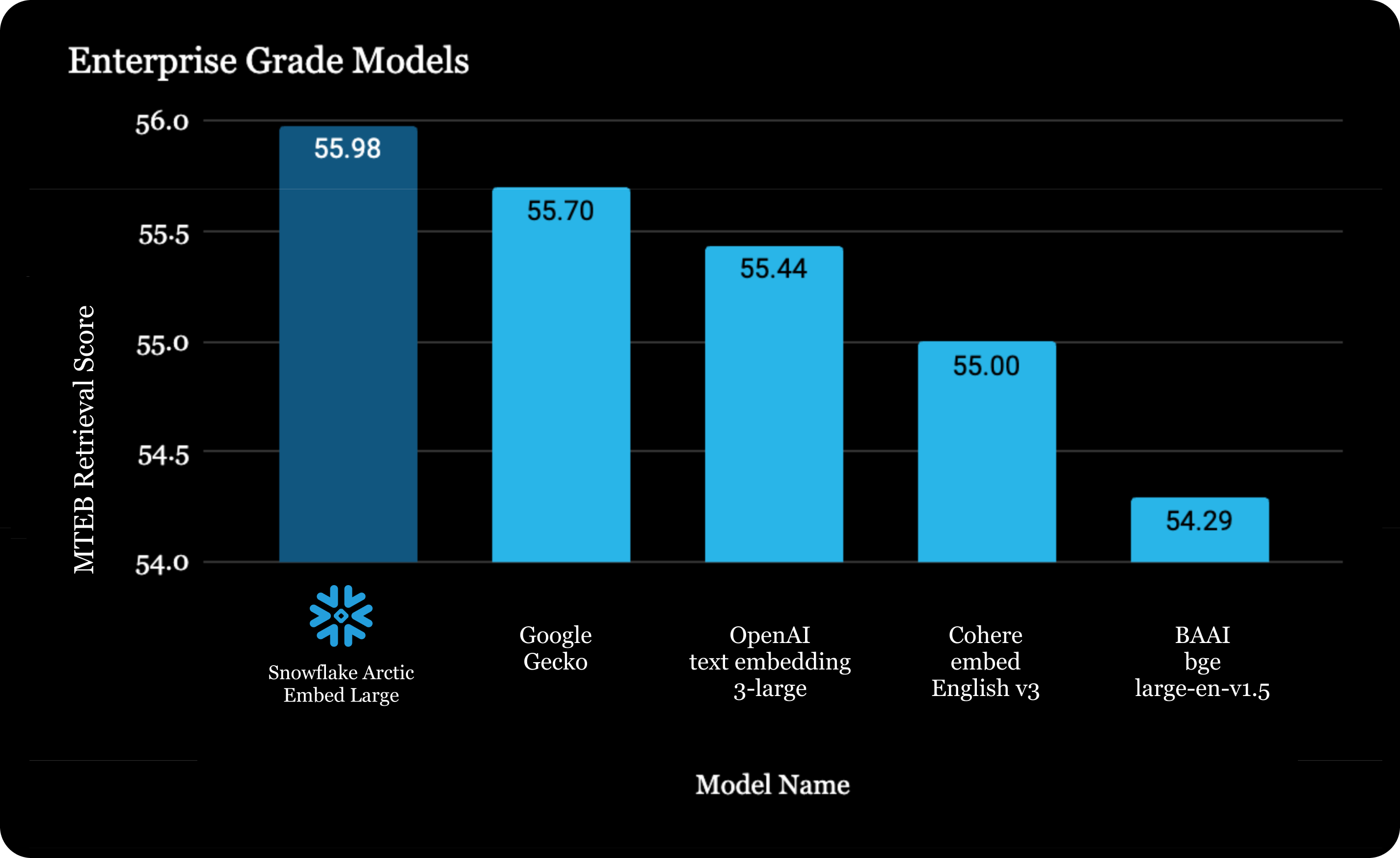
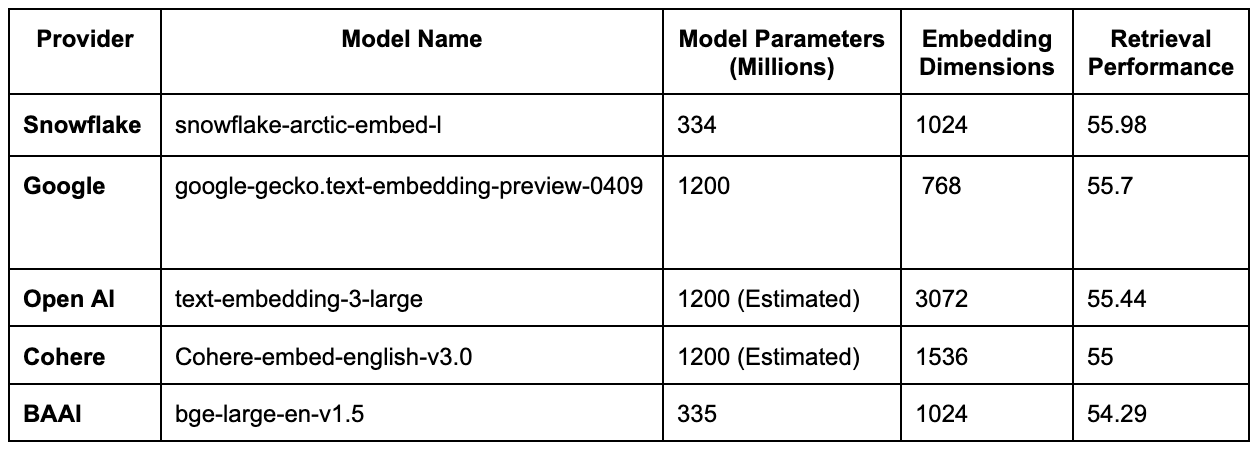
As of April 16, 2024, snowflake-arctic-embed-l is the most capable open-source model that can be used in production based on its performance-to-size ratio. Models that outperform snowflake-arctic-embed-l, such as SFR-Embedding-Mistral, widely available among embedding model providers, have a vector dimensionality four times larger (1024 vs. 4096) and have over 20x more parameters (334 million vs. 7.1 billion). With the Apache 2 licensed Snowflake Arctic embed family of models, organizations now have one more open alternative to black-box API providers such as Cohere, OpenAI, or Google.
As shown in the table below, snowflake-arctic-embed-l outperforms retrieval performance, having one-quarter of the estimated parameters and one-third of the dimensions compared to Open AI.
Our models are incredibly easy to integrate with your existing search stack. Available directly from Hugging Face with an Apache 2 license, you can use this model for retrieval with five simple lines of Python.
import torch
from transformers import AutoModel, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('Snowflake/snowflake-arctic-embed-l')
model = AutoModel.from_pretrained('Snowflake/snowflake-arctic-embed-l', add_pooling_layer=False)
documents = ['Snowflake is the Data Cloud!', 'Arctic-embed is a state of the art text embedding model.']
embeddings = model(**tokenizer(documents, padding=True, truncation=True, return_tensors='pt', max_length=512))[0][:, 0]Now, for the part, everyone is likely curious about: how are these models so good? The answer is simple: effective techniques from web searching are equally applicable to training text embedding models. While we will discuss all our findings in an upcoming in-depth technical report, we outline many of our findings on how to train a state-of-the-art embedding model and how to use Snowflake to process training data. At a high level, we found that improved sampling strategies and competence-aware hard-negative mining could lead to massive improvements in quality. We would also be remiss to say that we did not build on the shoulders of giants, and in our training, we leverage initialized models such as (bert-base-uncased, nomic-embed-text-v1-unsupervised, e5-large-unsupervised, sentence-transformers/all-MiniLM-L6-v2).
When our findings were combined with web search data and a quick iteration loop to gradually improve our model until the performance was something we were excited to share with the broader community. Notably, none of our significant improvements came from a massive expansion of the computing budget. All of our experiments used 8 H100 GPUs!
This release is the first of many steps in our commitment to provide our customers with the best models for use in common enterprise use cases such as RAG and search. Using our deep expertise in search derived from the Neeva acquisition, combined with the incredible data processing power of Snowflake’s Data Cloud, we have shared with the community a set of efficient models that provide the retrieval quality our customers require. We are rapidly expanding the types of models we train and the targeted workloads. Not only are we working on models, but we are also developing novel benchmarks that we will use to guide the development of the next generation of models. If you are interested in improving our models, have any suggestions, or want to join us in building the future, please reach out.
We thank our modeling engineers, Danmei Xu, Luke Merrick, Gaurav Nuti, and Daniel Campos, for making these great models possible. We thank our leadership, Himabindu Pucha, Kelvin So, Vivek Raghunathan, and Sridhar Ramaswamy, for supporting this work. We also thank the open-source community for producing the great models we could build on top of and making these releases possible. Finally, we thank the researchers who created BEIR and MTEB benchmarks. It is largely thanks to their tireless work to define what “better” looks like that we could improve model performance.
The post Snowflake Launches the World’s Best Practical Text-Embedding Model for Retrieval use Cases appeared first on Snowflake.
Credit: Edgar Cervantes / Android Authority TL;DR Facebook is getting an AI mode for enhanced search and exploration. Camera roll […]
Build advanced personal work agents: Snowflake CoWork is the personal work agent for every knowledge worker. It understands your data […]
Figure 1: The full workflow where CoCo validates, scaffolds, builds, deploys and tests a Snowpark stored procedure from one conversational […]
Our services help both the big and small organisations in the identification of security breaches and provide outclass solutions to prevent any potential harm.